Category Archives: Julia

IJulia on Amazon EC2 instance
Table of Contents
In this blog post I want to give a description of how to set up a running IJulia server on an Amazon EC2 instance. Although there already are some useful resources on the topic out there, I didn’t find any comprehensive tutorial yet. Hence, I decided to write down my experiences, just in case it might be a help for others.
1 What for?
At this point, you might think: “okay – but what for?”. Well, what you get with Amazon AWS is a setting where you can easily load a given image on a computer that can be chosen from a range of different memory and processing characteristics (you can find a list of available instances here). In addition, you can also store some private data on a separate volume with Amazon’s Elastic Block Store. So taking both components together, this allows fast setup of the following workflow:
- choose a computer with optimal characteristics for your task
- load your ready-to-go working environment with all relevant software components pre-installed
- mount an EBS volume with your private data
And your customized computer is ready for work!
So, what you get is a flexible environment that you can either use for selected tasks with high computational requirements only, or that you steadily use with a certain baseline level of CPU performance and only scale it up when needed. This way, for example, you could outsource computations from your slow netbook to the Amazon cloud whenever the weather allows you to do your work outside in your garden. Any easy to transport and lightweight netbook already provides you with an entrance to huge computational power in the Amazon cloud. However, compared to a moderately good local computer at home, it doubt that the Amazon cloud will be a cost-efficient alternative for permanent work yet. Besides, you always have the disadvantage of having to rely on a good internet connection, which especially becomes problematic when traveling.
Anyways, I am sure you will find your own use cases for IJulia in the cloud, so let’s get started with the setup.
2 Setting up an Amazon AWS account
The first step, of course, is setting up an account at Amazon web services. You can either log in with an existing Amazon account, or just create a completely new account from scratch. At this step, you will already be required to leave your credit card details. However, Amazon automatically provides you with a free usage tier, comprising (among other benefits) 750 hours of free EC2 instance usage, as well as 30 GB of EBS storage. For more details, just take a look at Amazon’s pricing webpage.
3 Setting up an instance
Logging in to your account will take you to the AWS Management Console: a graphical user interface that allows managing all of your AWS products. Should you plan on making some of your products available to other users as well (employees, students, …), you could easily assign rights to groups and users through their AWS Identity and Access Management (IAM), so that you are the only person with access to the full AWS Management Console.
Now let’s create a new instance. In the overview, click on EC2 to get to the EC2 Dashboard, where you can manage and create Amazon computing instances. You need to specify the region where your instance should physically be created, which you can select in the upper right corner. Then, click on instances on the left side, and select Launch Instance to access the step by step instructions.
In the first step you need to select a basic software equipment that your instance should use. This determines your operating system, but also could comprise additional preinstalled software. You can select from a range of Amazon Machine Images (AMI), which could be images that are put together either by Amazon, by other members of the community or by yourself. At the end of the setup, we will save our preinstalled IJulia server as AMI as well, so that we can easily select it as ready-to-go image for future instances. For now, however, we simply select an image with a basic operating system installed. For the instructions described here, I select Ubuntu Server 14.04 LTS.
In the next step we now need to pick the exact memory and processing characteristics for our instance. For this basic setup, I will use a t2.micro instance type, as it is part of the free usage tier in the first 12 months. If you wanted to use Amazon EC2 for computationally demanding tasks, you would select a type with better computational performance.
In the next two steps, Configure Instance and Add Storage, I simply stick with the default values. Only in step 5 I manually add some tags to the instance. Tags can be added as key-value pairs. So, for example, we could use the following tags to describe our instance:
- task = ijulia,
- os = ubuntu,
- cpu = t2.micro
By now, all characteristics of the instance itself are defined, and we only need to determine the traffic that is allowed to reach our instance. In other words: we have defined a virtual computer in Amazon’s cloud – but how can we communicate with it?
In general, there are several ways to access a remote computer. The standard way on Linux computers would be through a terminal with SSH connection. This way, we can execute commands at the remote computer, which allows the installation of software, for example. In addition, however, we might want to communicate with the remote computer through other channels than the terminal. For example, in our case we want to access the computing power of the remote through an IJulia tab in our browser. Hence, we need to determine all ways through which a communication to the remote should be allowed. For security reasons, you want to keep these communication channels as sparse and restricted as possible. Still, you need to allow some of these channels in order to use our instance in the manner that you want to. In our case, we add a new rule that allows access to our instance through the browser, and hence select All TCP as its type. Be warned, however, that I am definitely not an expert on computer security issues, so that this rule might be overly permissive. Ultimately, you only want to permit communication through https with a given port (8998 in our example), and there might be better ways to achieve this. Still, I will add an additional layer of protection by restricting permission to my current IP only. If you do this, however, then you most likely need to adapt your settings each time that you restart your computer, as your IP address might change. Anyways, in many cases your instance will only live temporarily, and will be deleted after completion of a certain task. Your security concerns for such a short-living instance hence might be rather limited. Either way, you can store your current settings as a new security group, so that you can select the exact same settings for some of your future instances. I will choose “IJulia all tcp” as name of the group.
Once you are finished with your security settings, click Review and Launch and confirm your current settings with Launch. This will bring up a dialogue that lets you exchange ssh keys between remote computer and local computer. You can either create a new key pair or choose an already existing pair. In any case, make sure that you will really have access to the chosen key afterwards, because it will be the only way to get full access to your remote. If you create a new pair, the key will automatically be downloaded to your computer. Just click Launch Instance afterwards, and your instance will be available in a couple of minutes.
4 Installing and configuring IJulia
Once your instance will be displayed as running you can connect to it through ssh. Therefore, we need to use the ssh key that we did get during the setup, which I stored in my download folder with name aws_ijulia_key.pem. First, however, we will need to change the permissions of the key, so that it can not be accessed by everyone. This step is mandatory – otherwise the ssh connection will fail.
chmod 400 ~/Downloads/aws_ijulia_key.pem
Now we are ready to connect. Therefore, we need to link to the ssh key through option -i. The address of your instance is composed of two parts. First, the username, which is ubuntu for the case of an Ubuntu operating system. And second, we need to copy the Public DNS of the instance, which we can find listed in the description when we select the instance in the AWS Management Console.
ssh -i ~/Downloads/aws_ijulia_key.pem ubuntu@ec2-54-76-169-215.eu-west-1.compute.amazonaws.com
Now that we have access to a terminal within our instance, we can use it to install all required software components for IJulia. First, we install Julia from the julianightlies repository.
sudo add-apt-repository ppa:staticfloat/julia-deps sudo add-apt-repository ppa:staticfloat/julianightlies sudo apt-get update sudo apt-get -y install julia
We now already could use Julia through the terminal. Then we need to install a recent version of ipython, which we can do using pip.
sudo apt-get -y install python-dev ipython python-pip sudo pip install --upgrade ipython
IJulia also requires some additional packages:
sudo pip install jinja2 tornado pyzmq
At last, we need to install the IJulia package:
julia -e 'Pkg.add("IJulia")'
At this step, we have installed all required software components, which we now only need to configure correctly.
The first thing we need to do is set up a secure way of connecting to IJulia through our browser. Therefore, we need to set a password that we will be required to type in when we log in. We will create this password within ipython. To start ipython on your remote, type
ipython
Within ipython, type the following
from IPython.lib import passwd passwd()
Now type in your password. For this demo, I chose ‘juliainthecloud’, equal to the setup here. IPython then prints out the encrypted version of this password, which in my case is
'sha1:32c75aa1c075:338b3addb7db1c3cb2e10e7b143fbc60be54c1be'
You will need this hashed password later, so you should temporarily store it in your editor.
We now can exit ipython again:
exit
As a second layer of protection, we need to create a certificate which our browser will automatically use when it communicates with our IJulia server. This way, we will not have to send our password in plain text to the remote computer, but the connection will be encrypted right away. In your remote terminal, type:
mkdir ~/certificates cd ~/certificates openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mycert.pem -out mycert.pem
You are asked to add some additional information to your certificate, but you can also skip all fields by pressing enter.
Finally, we now only need to configure IJulia. Therefore, we add the following lines to the julia profile within ipython. This profile should already have been created through the installation of the IJulia package, so that we can open the respective file with vim:
vim ~/.ipython/profile_julia/ipython_notebook_config.py
Press i for insert mode, and after
c = get_config()
add the following lines (which I myself did get from here):
# Kernel config c.IPKernelApp.pylab = 'inline' # if you want plotting support always # Notebook config c.NotebookApp.certfile = u'/home/ubuntu/certificates/mycert.pem' c.NotebookApp.ip = '*' c.NotebookApp.open_browser = False c.NotebookApp.password = u'sha1:32c75aa1c075:338b3addb7db1c3cb2e10e7b143fbc60be54c1be' # It is a good idea to put it on a known, fixed port c.NotebookApp.port = 8998
Make sure that you did set c.NotebookApp.password to YOUR hashed password from before.
To leave vim again, press escape to end insert mode and :wq to save and quit.
5 Starting and connecting to IJulia server
We are done with the configuration, so that we now can connect to our IJulia server. To start the server on the remote, type
sudo ipython notebook --profile=julia # nohup ipython notebook --profile julia > ijulia.log &
And to connect to your server, open a browser on your local machine and go to
https://ec2-54-76-169-215.eu-west-1.compute.amazonaws.com:8998
This will pop up a warning that the connection is untrust. Don’t worry, this is just because we are using the encryption that we did set up ourselves, and this certificate is not officially registered. Once you allow the connection, an IJulia logo appears, and you will be prompted for your password.
Note, however, that the Public DNS of your instance changes whenever you stop your instance from running. Hence, you need to type a different URL when you connect to IJulia the next time.
6 Store as AMI
Now that we have done all this work, we want to store the exact configuration of our instance as our own AMI to be able to easily load it on any EC2 instance type in the future. Therefore, we simply stop our running instance in the AWS Management Console (after we also stopped the running IJulia server of course). Right-click on it as soon as the Instance State says stopped. Choose create image, select an appropriate name for your configuration, and you’re done. The next time you launch a new image, you can simply select this AMI instead of the Ubuntu 14.04 AMI that we did use previously.
However, creating an image of your current instance requires you to store a snapshot of your volume in your elastic block store, which might cause additional costs depending on your AWS profile. Using Amazon’s free usage tier, you have 1GB free snapshot storage at your disposal. Due to compression, your snapshot should be smaller in storage size than the original 8GB of your volume. Nevertheless, I do not yet know where to look up the overall storage size of my snapshots (determining the size of individual snapshots if you have multiple snapshots is even impossible). I only can say that Amazon did not bill me for anything yet, so I assume that the snapshot’s size should be smaller than 1GB.
7 Add volume
In order to have your data available for multiple instances, you should store it on a separate volume, which then can be attached to any instance you like. This also allows easy duplication of your data, so that you can attach one copy of it to your steadily running t2.micro instance, while the other one gets attached to some temporary instance with greater computational power in order to perform some computationally demanding task.
For creation and mounting of a data volume we largely follow the steps shown in the documentation.
On the left side panel, click on Volumes, then select Create Volume. As size we choose 5 GB, as this should leave us with enough free storage size in order to simultaneously run two instances, each with its own copy of personal data mounted. Also, we choose to not encrypt our volume, as t2.micro instances do not support encrypted volumes.
Now that the volume is created, we need to attach it to our running instance. Right-click on the volume and select Attach Volume. Type in the ID of your running instance, and as your device name choose /dev/sdf as proposed for linux operating systems.
Connect to your running instance with ssh, and display all volumes with the lsblk command in order to find the volume name. In my case, the new attached volume displays as xvdf. Now, since we created a new volume from scratch, we additionally need to format it. Be careful to not conduct this step if you attach an already existing volume with data, as it would delete all of your data! For my volume name, the command is
sudo mkfs -t ext4 /dev/xvdf
The device can now be mounted anywhere in your file system. Here we will mount it as folder research in the home directory.
sudo mkdir ~/research sudo mount /dev/xvdf /home/ubuntu/research
And, in case you need it at some point, you can unmount it again with
umount -d /dev/xvdf
8 Customization
Well, now we know how to get an IJulia server running. To be honest, however, this really is only half of the deal if you want to use it for more than just some on-the-fly experimenting. For more elaborate work, you need to be able to also conveniently perform the following operations at your Amazon remote instance:
- editing files on the remote
- copying files to and from the remote
There are basically two ways that allow you to edit files on the remote. First, you use some way of editing files directly through the terminal. For example, you could open a vim session in your terminal on the remote itself. Second, you work with a local editor that allows to access files on a remote computer via ssh. As emacs user, I stick with this approach, as emacs tramp allows working with remote files as if they were local.
For synchronization of files to the remote I use git, as I host all of my code on github and bitbucket. However, I also want my remote to communicate with my code hosting platforms through ssh without any additional password query. In principle, one could achieve this through the standard procedure: creating a key pair on the remote, and copying the public key to the respective file hosting platform. However, this could become annoying, given that we have to perform it whenever we launch a new instance in the future. There is a much easier way to enable communication between remote server and github / bitbucket: using SSH agent forwarding. What this does, in simple terms, is passing your local ssh keys on to your remote computer, which is then allowed to use them for authentication itself. To set this up, we have to add some lines to ./ssh/config (take a look at this post for some additional things that you could achieve with your config file). And since we are already editing the file, we also take the chance to set an alias aws_julia_instance for our server and automatically link to the required login ssh key file. Our config file now is
Host aws_julia_instance
HostName ec2-54-76-169-215.eu-west-1.compute.amazonaws.com
User ubuntu
IdentityFile ~/Downloads/aws_ijulia_key.pem
ForwardAgent yes
Remember: you have to change the HostName in your config file whenever you stop your instance, since the Public DNS changes.
Given the settings in our config file, we now can access our remote through ssh with the following simple command:
ssh aws_julia_instance
And, given that we have set up ssh access to github and bitbucket on our local machine, we can use these keys on the remote as well.
As a last convenience for the synchronization of files on your remote I recommend the use of myrepos, which allows you to easily keep track of all modifications in a whole bunch of repositories. You can install it with
mkdir ~/programs cd ~/programs git clone https://github.com/joeyh/myrepos.git cd /usr/bin/ sudo ln -s ~/programs/myrepos/mr
Coping with missing stock price data
1 Missing stock price data
When downloading historic stock price data it happens quite frequently that some observations in the middle of the sample are missing. Hence the question: how should we cope with this? There are several ways how we could process the data, each approach coming with its own advantages and disadvantages, and we want to compare some of the most common approaches in this post.
In any case, however, we want to treat missing values as NA and not as Julia’s built-in NaN (a short justification on why NA is more suitable can be found here). Hence, data best should be treated through DataFrames or – if the data comes with time information – through type Timenum from the TimeData package. In the following, we will use these packages in order to show some common approaches to deal with missing stock price data using an artificially made up data set that shall represent logarthmic prices.
The reason why we are looking at logarthmic prices and returns instead of normal prices and net returns is just that logarithmic returns are defined as simple difference between logarithmic prices of successive days:
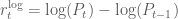
This way, our calculations simply involve nicer numbers, and all results equally hold for normal prices and returns as well.
We will be using the following exemplary data set of logarthmic prices for the comparison of different approaches:
using TimeData using Dates using Econometrics df = DataFrame() df[:stock1] = @data([100, 120, 140, 170, 200]) df[:stock2] = @data([110, 120, NA, 130, 150]) dats = [Date(2010, 1, 1):Date(2010, 1, 5)] originalPrices = Timenum(df, dats)
| idx | stock1 | stock2 |
| 2010-01-01 | 100 | 110 |
| 2010-01-02 | 120 | 120 |
| 2010-01-03 | 140 | NA |
| 2010-01-04 | 170 | 130 |
| 2010-01-05 | 200 | 150 |
One possible explanation for such a pattern in the data could be that the two stocks are from different countries, and only the country of the second stock has a holiday at January the 3rd.
Quite often in such a situation, people just refrain from any deviations from the basic calculation formula of logarithmic returns and calculate the associated returns as simple differences. This way, however, each missing observation NA will lead to two NAs in the return series:
simpleDiffRets = originalPrices[2:end, :] .- originalPrices[1:(end-1), :]
| idx | stock1 | stock2 |
| 2010-01-02 | 20 | 10 |
| 2010-01-03 | 20 | NA |
| 2010-01-04 | 30 | NA |
| 2010-01-05 | 30 | 20 |
For example, this also is the approach followed by the PerformanceAnalytics package in R:
library(tseries)
library(PerformanceAnalytics)
stockPrices1 <- c(100, 120, 140, 170, 200)
stockPrices2 <- c(110, 120, NA, 130, 150)
## combine in matrix and name columns and rows
stockPrices <- cbind(stockPrices1, stockPrices2)
dates <- seq(as.Date('2010-1-1'),by='days',length=5)
colnames(stockPrices) <- c("A", "B")
rownames(stockPrices) <- as.character(dates)
(stockPrices)
returns = Return.calculate(exp(stockPrices), method="compound")
| nil | nil |
| 20 | 10 |
| 20 | nil |
| 30 | nil |
| 30 | 20 |
When we calculate returns as the difference between successive closing prices 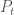
Thinking about returns this way, it obviously makes sense to assign a value of NA to each day of the return series where a stock exchange was closed due to holiday, since there simply are no stock price movements on that day. But why would we set the next day’s return to NA as well?
In other words, we should distinguish between two different cases of NA values for our prices:
NAoccurs because the stock exchange was closed this day and hence there never were any price movements- the stock exchange was open that day, and in reality there were some price changes. However, due to a deficiency of our data set, we do not know the price of the respective day.
For the second case, we really would like to have two consecutive values of NA in our return series. Knowing only the prices in 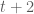
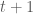
For the first case, however, it seems unnecessarily rigid to force the return series to have two NA values: allocating all of the two-day price increase to the one day where the stock exchange was open, and a missing value NA to the day that the stock exchange was closed doesn’t seem to be too arbitrary.
This is how returns are calculated by default in the (not yet registered) Econometrics package.
logRet = price2ret(originalPrices, log = true)
| idx | stock1 | stock2 |
| 2010-01-02 | 20 | 10 |
| 2010-01-03 | 20 | NA |
| 2010-01-04 | 30 | 10 |
| 2010-01-05 | 30 | 20 |
And, the other way round, aggregating the return series again will also keep NAs for the respective days, but otherwise perform the desired aggregation. Without specified initial prices, aggregated prices will all start with value 0 for logarithmic prices, and hence express something like normalized prices that allow a nice comparison of different stock price evolutions.
normedPrices = ret2price(logRet, log = true)
| idx | stock1 | stock2 |
| 2010-01-01 | 0 | 0 |
| 2010-01-02 | 20 | 10 |
| 2010-01-03 | 40 | NA |
| 2010-01-04 | 70 | 20 |
| 2010-01-05 | 100 | 40 |
To regain the complete price series (together with a definitely correct starting date), one simply needs to additionally specify the original starting prices.
truePrices = ret2price(logRet, originalPrices, log = true)
| idx | stock1 | stock2 |
| 2010-01-01 | 100 | 110 |
| 2010-01-02 | 120 | 120 |
| 2010-01-03 | 140 | NA |
| 2010-01-04 | 170 | 130 |
| 2010-01-05 | 200 | 150 |
In some cases, however, missing values NA may not be allowed. This could be a likelihood function that requires real values only, or some plotting function. For these cases NAs easily can be removed through imputation. For log price plots, a meaningful way would be:
impute!(truePrices, "last")
| idx | stock1 | stock2 |
| 2010-01-01 | 100 | 110 |
| 2010-01-02 | 120 | 120 |
| 2010-01-03 | 140 | 120 |
| 2010-01-04 | 170 | 130 |
| 2010-01-05 | 200 | 150 |
However, for log returns, the associated transformation then would artificially incorporate values of 0:
impute!(logRet, "zero")
| idx | stock1 | stock2 |
| 2010-01-02 | 20 | 10 |
| 2010-01-03 | 20 | 0 |
| 2010-01-04 | 30 | 10 |
| 2010-01-05 | 30 | 20 |
As an alternative to replacing NA values, one could also simply remove the respective dates from the data set. Again, there are two options how this could be done.
First, one could remove any missing observations directly in the price series:
originalPrices2 = deepcopy(originalPrices) noNAprices = convert(TimeData.Timematr, originalPrices2, true)
| idx | stock1 | stock2 |
| 2010-01-01 | 100 | 110 |
| 2010-01-02 | 120 | 120 |
| 2010-01-04 | 170 | 130 |
| 2010-01-05 | 200 | 150 |
For the return series, however, we then have a – probably large – multi-day price jump that seems to be a single-day return. In our example, we suddenly observe a return of 50 for the first stock.
logRet = price2ret(noNAprices)
| idx | stock1 | stock2 |
| 2010-01-02 | 20 | 10 |
| 2010-01-04 | 50 | 10 |
| 2010-01-05 | 30 | 20 |
A second way to eliminate NAs would be to remove them from the return series.
logRet = price2ret(originalPrices) noNAlogRet = convert(TimeData.Timematr, logRet, true)
| idx | stock1 | stock2 |
| 2010-01-02 | 20 | 10 |
| 2010-01-04 | 30 | 10 |
| 2010-01-05 | 30 | 20 |
However, deriving the associated price series for this processed return series will then lead to deviating end prices:
noNAprices = ret2price(noNAlogRet, originalPrices)
| idx | stock1 | stock2 |
| 2010-01-01 | 100 | 110 |
| 2010-01-02 | 120 | 120 |
| 2010-01-04 | 150 | 130 |
| 2010-01-05 | 180 | 150 |
as opposed to the real end prices
originalPrices
| idx | stock1 | stock2 |
| 2010-01-01 | 100 | 110 |
| 2010-01-02 | 120 | 120 |
| 2010-01-03 | 140 | NA |
| 2010-01-04 | 170 | 130 |
| 2010-01-05 | 200 | 150 |
The first stock now suddenly ends with a price of only 180 instead of 200.
2 Summary
The first step when facing a missing price observation is to think whether it might make sense to treat only one return as missing, assigning the complete price movement to the other return. This is perfectly reasonable for days where the stock market really was closed. In all other cases, however, it might make more sense to calculate logarithmic returns as simple differences, leading to two NAs in the return series.
Once there are NA values present, we can chose between three options.
2.1 Keeping NAs
Keeping NA values might be cumbersome in some situations, since some functions might only be working for data without NA values.
2.2 Replacing NAs
In cases where NAs may not be present, there sometimes might exist ways of replacing them that perfectly make sense. However, manually replacing observations in some way means messing with the original data, and one should be cautious to not incorporate any artificial patterns this way.
2.3 Removing NAs
Obviously, when dates with NA values for only some variables are eliminated completely, we simultaneously lose data for those variables where observations originally were present. Furthermore, eliminating cases with NAs for returns will lead to price evolutions that are different to the original prices.
2.4 Overview
Possible prices:
| idx | simple diffs | single NA | replace \w 0 | rm NA price | rm NA return |
| 2010-01-01 | 100, 110 | 100, 110 | 100, 100 | 100, 110 | 100, 110 |
| 2010-01-02 | 120, 120 | 120, 120 | 120, 120 | 120, 120 | 120, 120 |
| 2010-01-03 | 140, NA | 140, NA | 140, 120 | ||
| 2010-01-04 | 170, 130 | 170, 130 | 170, 130 | 170, 130 | 150, 130 |
| 2010-01-05 | 200, 150 | 200, 150 | 200, 150 | 200, 150 | 180, 150 |
Possible returns:
| idx | simple diffs | single NA | replace \w 0 | rm NA price | rm NA return |
| 2010-01-02 | 20, 10 | 20, 10 | 20, 10 | 20, 10 | 20, 10 |
| 2010-01-03 | 20, NA | 20, NA | 20, 0 | ||
| 2010-01-04 | 30, NA | 30, 10 | 30, 10 | 50, 10 | 30, 10 |
| 2010-01-05 | 30, 20 | 30, 20 | 30, 20 | 30, 20 | 30, 20 |
Element-wise mathematical operators and iterator slides
I recently did engage in a quite elaborate discussion on the julia-stats mailing list about mathematical operators for DataFrames in Julia. Although I still do not agree with all of the arguments that were stated (at least not yet), I did get a very comforting feeling about the lively and engaged Julia community once again. Even one of the most active and busiest community members, John Myles White, did take the time to elaborately explain his point of view in the discussion – and this just might be the even higher good to me. Different opinions will always be part of any community. But it is the transparency of the discussions that tell you how strong a community is.
Still, however, mathematical operators are important to me, as I am quite frequently working with strictly real numeric data: no Strings, and no columns of categorical IDs. Given Julia’s expressive language, it would be quite easy to implement any desired mathematical operators for DataFrames on my own. However, I decided to follow what seems to be the consensus of the DataFrame developers, and hence refrain from any individual deviations in this direction. Alternatively, I decided to simply relate any element-wise operators of multi-column DataFrames to DataArray arithmetic, which allow most mathematical operators for individual columns. Viewed from this perspective, element-wise DataFrame operators are nothing else than operators that are successively applied to individual columns of a DataFrame, which are DataArrays.
As a consequence of this, I had to deepen my understanding of iterators, comprehensions and functions like vcat, map and reduce. For future reference, I did sum up my insights in a slide deck, which anybody who is interested could find here, or as part of my IJulia notebook collection here.
For those of you who are using the TimeData package, the current road-map regarding mathematical operators will be the following: any types that are constrained to numeric values only (including the extension to NA values) will carry on providing mathematical operators. These operators do perform some minimal checks upfront, in order to minimize risk of meaningless applications (for example, only adding up columns with equal names, equal dates,…). Furthermore, for any type that allows values other than numeric data these mathematical operators will not be defined. Hence, anybody in need of element-wise arithmetic for numeric data could easily make use of either Timematr or Timenum types (even if you do not need any time index). If you do, however, make sure to not mix up real numeric data and categorical data: applying mathematical operators or statistical functions like mean to something like customer IDs most likely will lead to meaningless results.
Julia syntax features
In one of my last posts I already tried to point out some advantages of Julia. Two of the main arguments are quite easily made: Julia is comparatively fast and free and open source. In addition, however, Julia also has a very powerful and expressive syntax compared to other programming languages, but this advantage is maybe less obvious to understand. Hence, I recently gave a short talk where I tried to extend a little bit on this point, while simultaneously also showing some of the convenient publishing feature of the IJulia backend. I thought I’d just share the outcome with you, just in case that anyone else could use the slides to convince some people of Julia’s powerful syntax. In addition to the slides, you can also access the presentation rendered as ijulia notebook here.
Julia language: A letter of recommendation
After spending quite some time using Julia (a programming language for technical computing) during the last few months, I am confident enough to provide kind of a “letter of recommendation” by now. Hence, I decided to list some of the features that make Julia appealing to me, while also interspersing some resources on Julia that I found helpful and worth sharing.
Inheriting type behavior in Julia
In object oriented programming languages, classes can inherit from classes of objects on a higher level in the class hierarchy. This way, methods of the superclass will apply to the subclass as well, given that they are not explicitly re-defined for the subclass. In many regards, super- and subclasses hence behave similarly, allowing the same methods to be applied and similar access behavior. Joined together, they hence build a coherent user interface.
In Julia, such a coherent interface for multiple types requires a little bit of extra work, since Julia does not allow subtyping for composite types. Nevertheless, Julia’s flexibility generally allows composite types to be constructed such that they emulate the behavior of some already existing type. This only requires a little bit of extra coding, but can be implemented efficiently through metaprogramming.
